@inproceedings{liu2025modeldiff,title={ModelDiff: Symbolic Dynamic Programming for Model-Aware Policy Transfer in Deep Q-Learning},author={Liu, Xiaotian and Jeong, Jihwan and Taitler, Ayal and Gimelfarb, Michael and Sanner, Scott},booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},year={2025},}
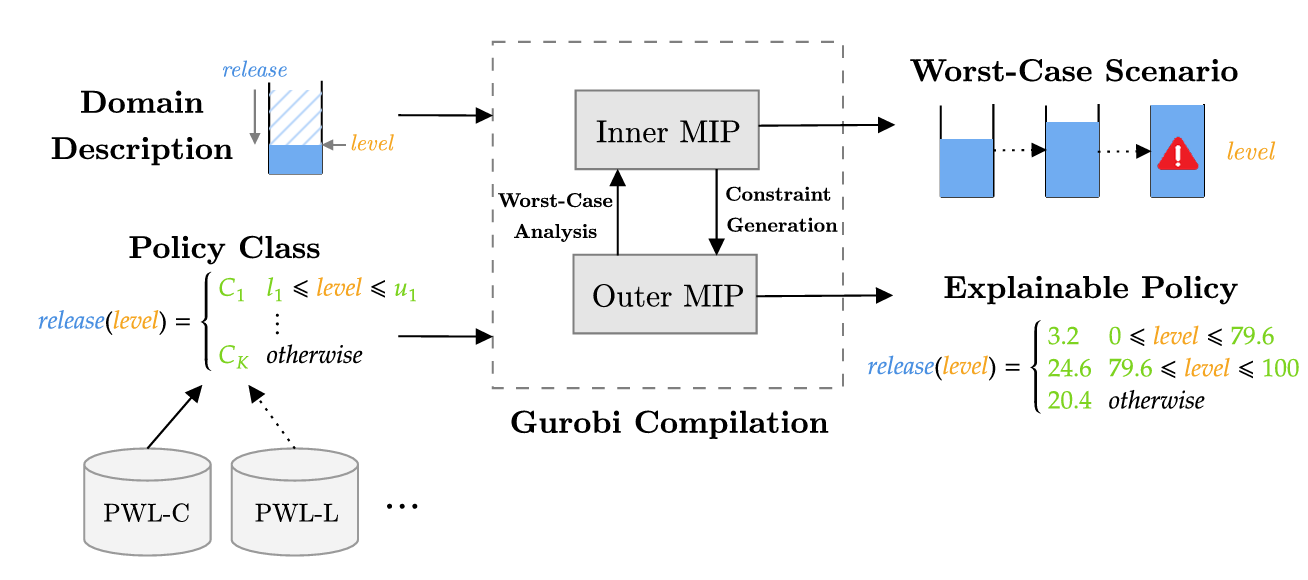
Bounded-Error Policy Optimization for Mixed Discrete-Continuous MDPs via Constraint Generation in Nonlinear Programming
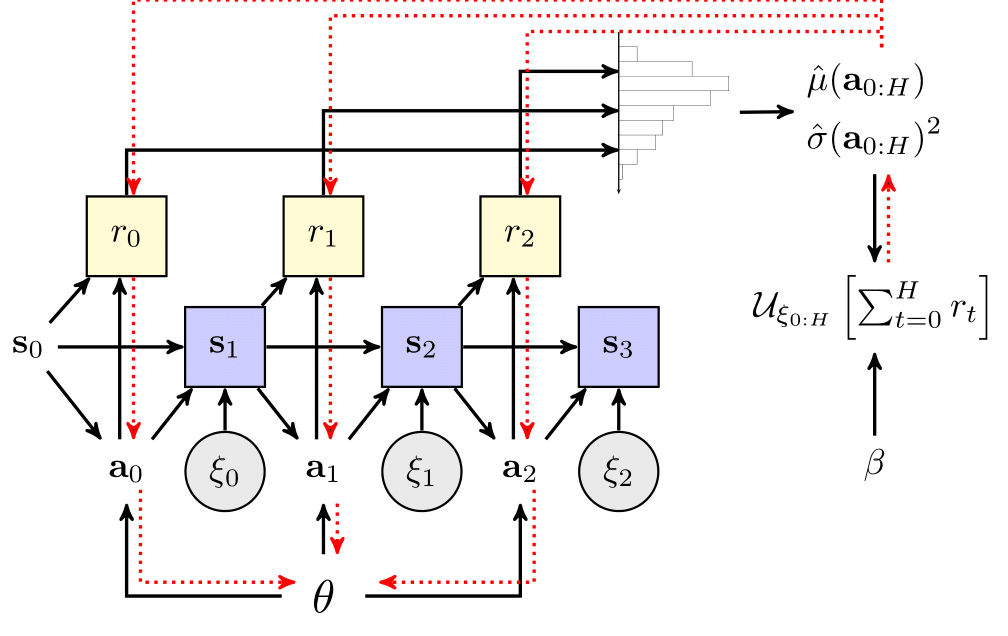
@inproceedings{gimelfarb2025constraint,title={Bounded-Error Policy Optimization for Mixed Discrete-Continuous MDPs via Constraint Generation in Nonlinear Programming},author={Gimelfarb, Michael and Taitler, Ayal and Sanner, Scott},booktitle={Integration of Constraint Programming, Artificial Intelligence, and Operations Research},publisher={Springer Nature Switzerland},year={2025},}
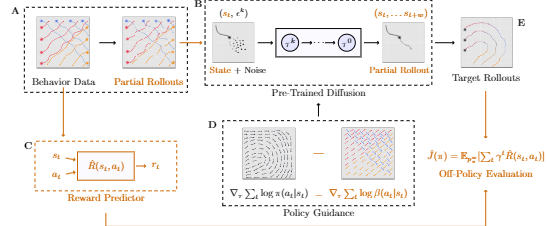
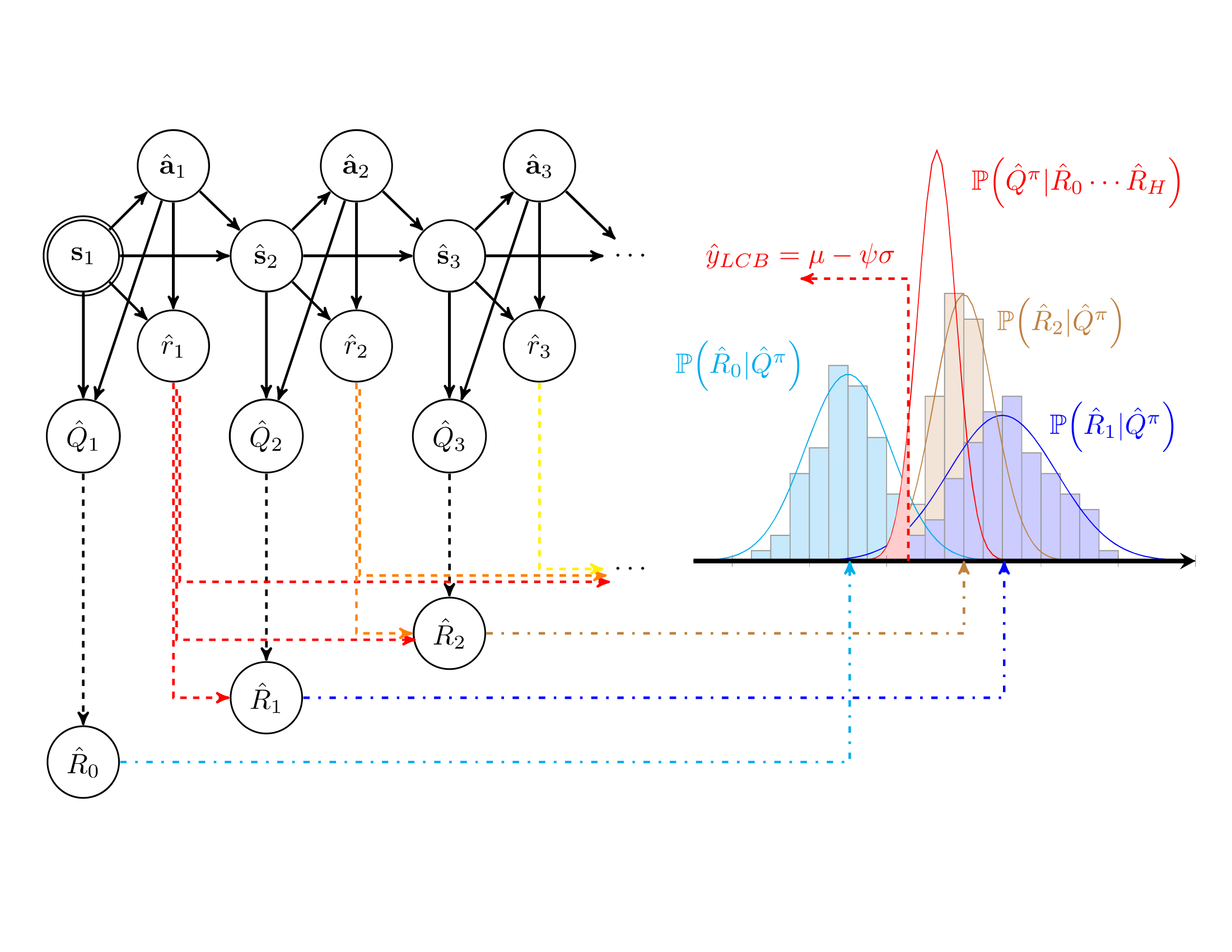
STITCH-OPE: Trajectory Stitching with Guided Diffusion for Off-Policy Evaluation
@inproceedings{goli2025stitchope,title={STITCH-OPE: Trajectory Stitching with Guided Diffusion for Off-Policy Evaluation},author={Goli, Hossein and Gimelfarb, Michael and de Lara, Nathan Samuel and Itkina, Masha and Nishimura, Haruki and Shkurti, Florian},booktitle={Robot Evaluation for the Real World},year={2025},}
2024
The 2023 International Planning Competition
Ayal Taitler, Ron Alford, Joan Espasa, Gregor Behnke, Daniel Fišer, Michael Gimelfarb, Florian Pommerening, Scott Sanner, Enrico Scala, Dominik Schreiber, and others
@article{taitler20242023,title={The 2023 International Planning Competition},author={Taitler, Ayal and Alford, Ron and Espasa, Joan and Behnke, Gregor and Fi{\v{s}}er, Daniel and Gimelfarb, Michael and Pommerening, Florian and Sanner, Scott and Scala, Enrico and Schreiber, Dominik and others},journal={AI Magazine},year={2024},}
JaxPlan and GurobiPlan: Optimization Baselines for Replanning in Discrete and Mixed Discrete-Continuous Probabilistic Domains
@inproceedings{gimelfarb2024jaxplan,title={JaxPlan and GurobiPlan: Optimization Baselines for Replanning in Discrete and Mixed Discrete-Continuous Probabilistic Domains},author={Gimelfarb, Michael and Taitler, Ayal and Sanner, Scott},booktitle={Proceedings of the International Conference on Automated Planning and Scheduling},year={2024},}
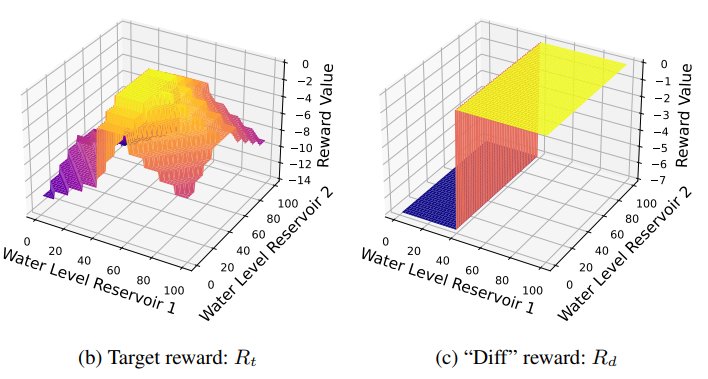
ModelDiff: Leveraging Models for Policy Transfer with Value Lower Bounds
@inproceedings{liu2024modeldiff,title={ModelDiff: Leveraging Models for Policy Transfer with Value Lower Bounds},author={Liu, Xiaotian and Jeong, Jihwan and Taitler, Ayal and Gimelfarb, Michael and Sanner, Scott},booktitle={PRL Workshop Series: Bridging the Gap Between AI Planning and Reinforcement Learning},year={2024},}
2023
Conservative bayesian model-based value expansion for offline policy optimization
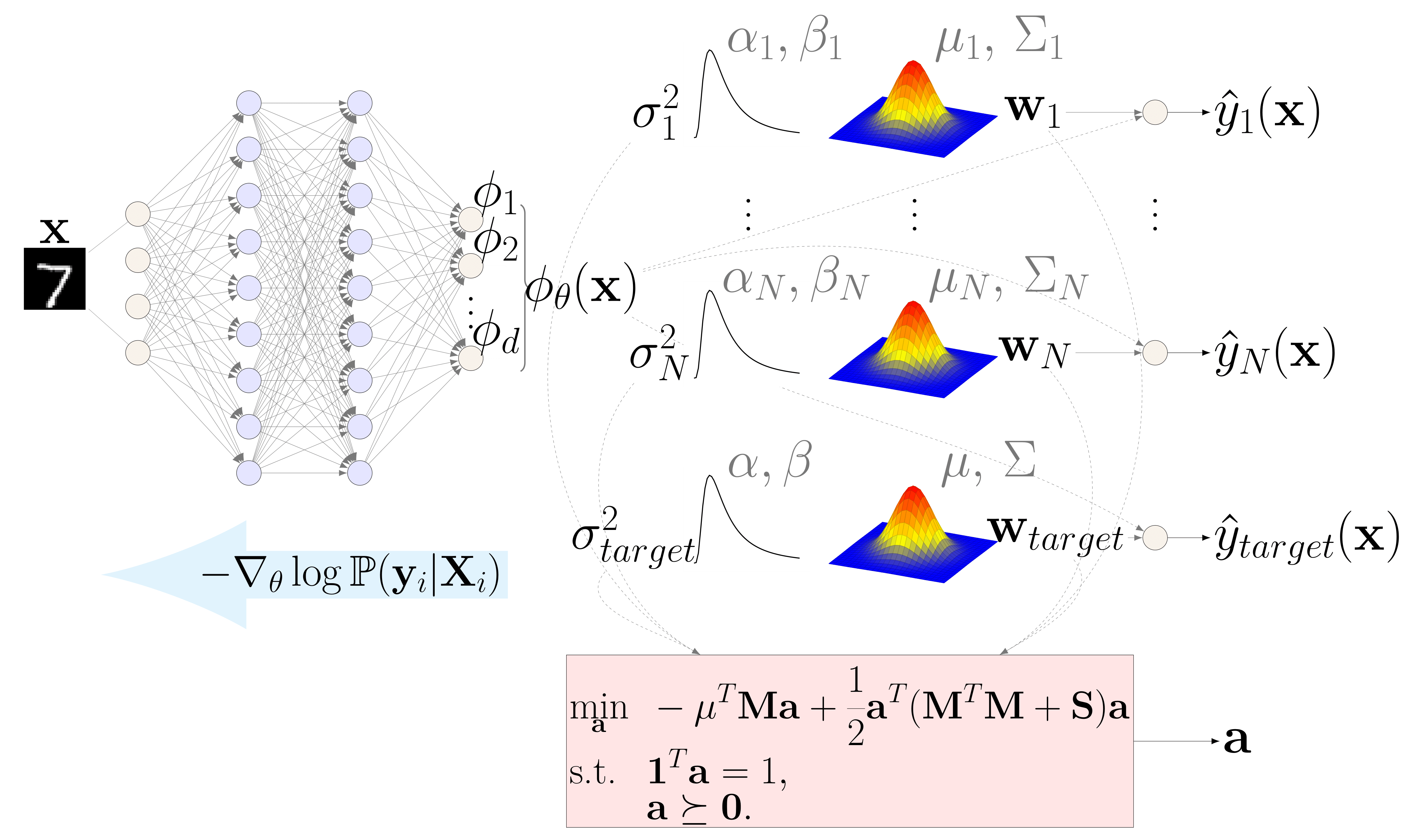
@inproceedings{jeong2023conservative,title={Conservative bayesian model-based value expansion for offline policy optimization},author={Jeong, Jihwan and Wang, Xiaoyu and Gimelfarb, Michael and Kim, Hyunwoo and Abdulhai, Baher and Sanner, Scott},booktitle={International Conference on Learning Representations},year={2023},}
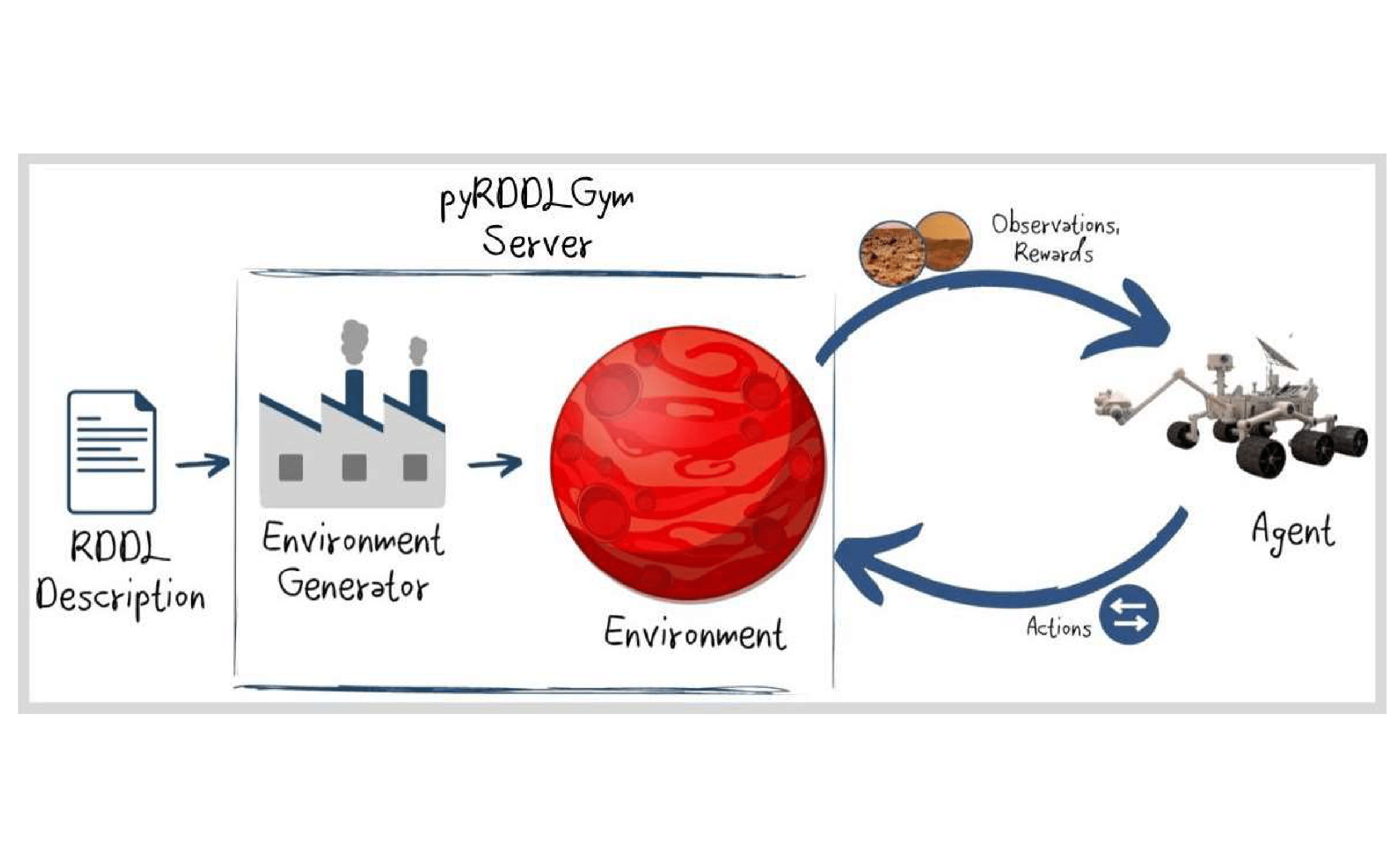
@inproceedings{taitler2023pyrddlgym,title={pyRDDLGym: From RDDL to Gym Environments},author={Taitler, Ayal and Gimelfarb, Michael and Jeong, Jihwan and Gopalakrishnan, Sriram and Mladenov, Martin and Liu, Xiaotian and Sanner, Scott},booktitle={PRL Workshop Series: Bridging the Gap Between AI Planning and Reinforcement Learning},year={2023},}
Thompson Sampling for Parameterized Markov Decision Processes with Uninformative Actions
@inproceedings{patton2022distributional,title={A Distributional Framework for Risk-Sensitive End-to-End Planning in Continuous MDPs},author={Patton, Noah and Jeong, Jihwan and Gimelfarb, Michael and Sanner, Scott},booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},year={2022},}
2021
Contextual policy transfer in reinforcement learning domains via deep mixtures-of-experts
@inproceedings{gimelfarb2021contextual,title={Contextual policy transfer in reinforcement learning domains via deep mixtures-of-experts},author={Gimelfarb, Michael and Sanner, Scott and Lee, Chi-Guhn},booktitle={Uncertainty in Artificial Intelligence},year={2021},}
Bayesian experience reuse for learning from multiple demonstrators
@inproceedings{gimelfarb2021bayesian,title={Bayesian experience reuse for learning from multiple demonstrators},author={Gimelfarb, Michael and Sanner, Scott and Lee, Chi-Guhn},booktitle={International Joint Conference on Artificial Intelligence},year={2021},}
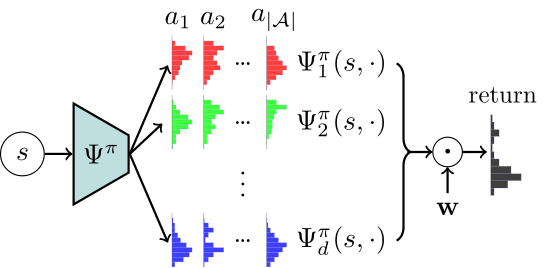
Risk-aware transfer in reinforcement learning using successor features
@inproceedings{gimelfarb2021risk,title={Risk-aware transfer in reinforcement learning using successor features},author={Gimelfarb, Michael and Barreto, Andr{\'e} and Sanner, Scott and Lee, Chi-Guhn},booktitle={Advances in Neural Information Processing Systems},year={2021},}
2020
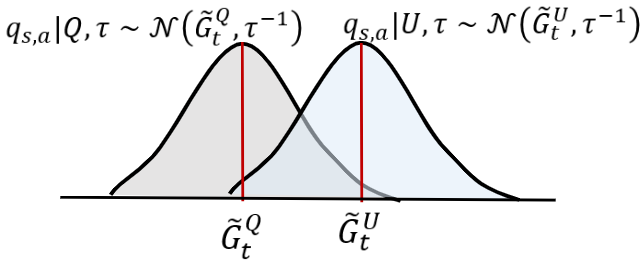
Epsilon-BMC: A Bayesian Ensemble Approach to Epsilon-Greedy Exploration in Model-Free Reinforcement Learning
@inproceedings{gimelfarb2020epsilon,title={Epsilon-BMC: A Bayesian Ensemble Approach to Epsilon-Greedy Exploration in Model-Free Reinforcement Learning},author={Gimelfarb, Michael and Sanner, Scott and Lee, Chi-Guhn},booktitle={Uncertainty in Artificial Intelligence},year={2020},}
2018
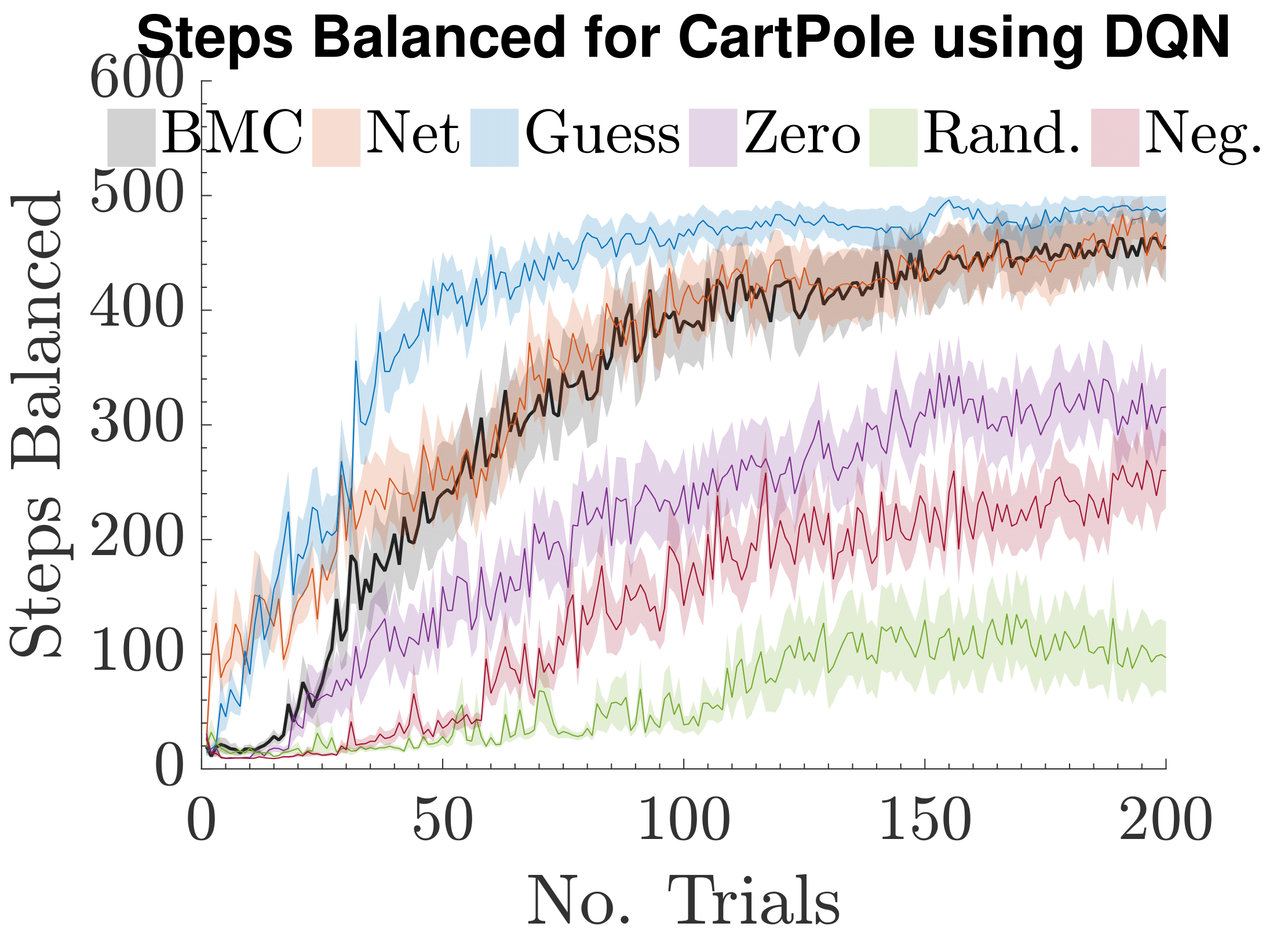
Reinforcement learning with multiple experts: A bayesian model combination approach
@inproceedings{gimelfarb2018reinforcement,title={Reinforcement learning with multiple experts: A bayesian model combination approach},author={Gimelfarb, Michael and Sanner, Scott and Lee, Chi-Guhn},booktitle={Advances in neural information processing systems},year={2018},}